
Present day organizations have become extremely large and complex. In fact, if you compared one to a human body, the data that keeps them running would have as network complex enough to compete with our own nervous system!
Not only do organizations generate a vast amount of data, the kinds of data generated also vary. Depending on the source and purpose of the data, there are also various different kinds of data frameworks and clusters that operate round the clock.
If this were not enough, things get even more complicated. To ensure consistency and reliability, these frameworks have to always be in constant sync with each other, or the functioning of the organization could come to a halt.
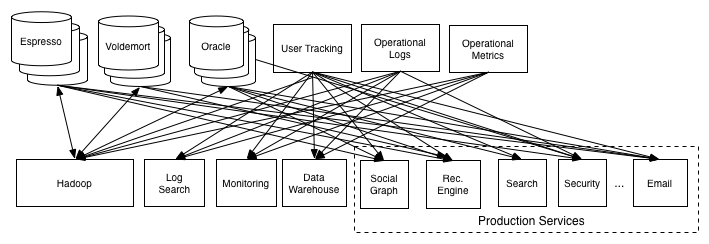
Jay Kreps, one of the founding members of the Apache Kafka project, cites the following as an example of how complicated the data integration in an organization can be:

Messy, isn’t it?
To give you a rough idea, the boxes at the top are data sources, or databases where the required information is available. The boxes at the bottom are data consumers. They include producer applications and storage locations – in other words, places where the information is required. The big traffic jam of data that you can see in the image has some sticky implications:
- There may be any amount of delay between data being generated and required for consumption
- Some data files may be extremely large and transporting them from one location to another may require specialized handling strategies such as partitioning.
- The data being handled may be sensitive, and complex networks might mean that the possibility of data loss is significant.
- Given the vast number of data pipelines, it’s rational to think that one or more of them will have a problem every other day, if they are to be maintained individually.
For several decades, organizations had a protocol to integrate all this data into a form that makes sense, and it was called an Enterprise Messaging System (EMS).
Here, the word “messaging” means either the request of a certain piece of data, or a notification of the data’s availability. EMS systems worked fine until about a decade ago when Big Data Analytics became a part of every organization’s daily workload.
This made data systems explode into impossible complex structures that existing EMSes just couldn’t keep up with. The problem grew so big, that one of the big guns of the organizations of our time, LinkedIn, decided to find a solution to it in 2011, and Kafka was conceived.
LinkedIn transferred the technology to Apache’s incubator, which later came up with the first free and open source Kafka release, just like all of Apache’s other products. Once you get to know the astounding power that Kafka provides, the fact that it’s free will only make things more unreal!
What is Kafka?
To put it technically, Kafka is a real time data stream processing framework. You can think of it as the next generation solution for the data that organisations create and work with. Or, as the developers of Kafka do, you can think of it as a data broker that negotiates the request and transfer of data from hundreds of sources to hundreds of destinations in real time.
To understand Kafka better, it is better to get familiar with the big picture first, before going into its individual components.
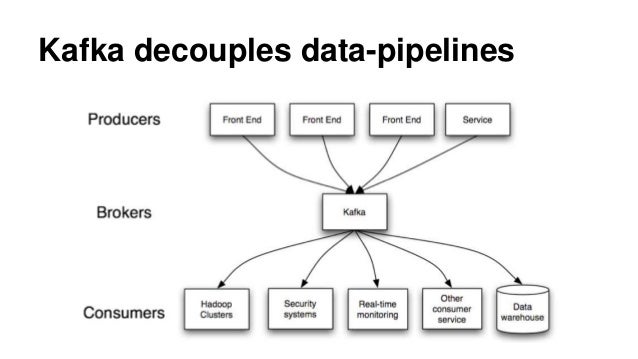
Just like Hadoop or Data Warehouses, Kafka is also a distributed computing cluster. This means that it is a large group of commodity computers interconnected to serve a common goal. Kafka’s location in an organization is central.
On one side, it has a crowd of systems that generate new data every second. On the other side, it has another crowd of apps and frameworks that need to use this data. Kafka’s job is to interact with each of these systems in real time and ensure that every bit of data is collected and sent exactly where an organisation would like.

Kafka Architecture
Now that we have a broad idea of where Kafka fits in inside an organisation’s data jungle, let us take a look at what goes on inside it, and how exactly it interacts with its surroundings.
Let’s first understand a few terms that you need to know before deep-diving into Apache Kafka:
1. Producer
An overtly simple answer would be that a producer is any application that sends data to Kafka. This data typically generates from an employee or a customer of the organisation. For example, the data might be a sales record of a particular customer (Say Mr X) generated after a purchase. It might also be the result of a query fired against one of the company’s many databases by an employee. Bottom line – if it sent new data to Kafka’s servers, then we’ll call it a producer. Here are two more things about producers:
- Every organization has to develop its own producer applications to get Kafka to suit its requirements. Rarely do producer applications come ready-made.
- Kafka sees all data fed into it as an array of bytes. It doesn’t matter if the data is a line of text, or the row of the table of a customer’s sales record, or the result of a query.
2. Consumer
A consumer is an application just like the producer, the only difference being that instead of sending data to Kafka, it asks for data. For example, the consumer might be another Hadoop or Spark cluster that’s looking for the customer sales data discussed earlier for big data analytics. To get the data, it would simply make a request for it to Kafka, and Kafka will produce the data as long as new data keeps flowing in, provided Hadoop has the right access privileges (more on that later!). For now, let’s learn two more things about Consumers:
- Producers don’t send any data with a consumer’s name written on it. Instead, it will simply have the data dumped into the Kafka server. After that, any application that has access privileges and requests the data can ask Kafka for it
- Data from a single producer might be required by a hundred consumers, or vice versa (i.e. data from a hundred producers might be required by a single consumer). This means traffic might build up on either side of Kafka’s core without notice.
3. Broker
In Kafka’s nomenclature, a “broker” is a single operational node in its cluster. Between every exchange of information between a producer and a consumer, there is a broker (or brokers!) silently doing its job. Typically, a Kafka cluster can have hundreds of brokers, each having their own lists of producer and consumer clients. Who decides which broker is assigned to which client? Well, that job is done by the ZooKeeper, as we will discuss later.
Right now, all that we need to know is that the just like a stock broker negotiates flow of money between a customer and a corporation, a Kafka broker negotiates the flow of data.
4. Topic
A “topic” is a unique identifier for each data pipeline that Kafka works with. To understand the need for a topic, let’s take an example. Suppose a consumer C asks a particular broker B for the customer sales data we talked about earlier, which was generated by producer P.
Now, the broker interacts with multiple producers, and might have sales data for any number of customers from any number of other producers sitting in its storage. How then, do they decide which data to send? A topic is an arbitrary ID given to the data stream connecting C, B, and P. This way, the broker can identify which data to send to which consumer!

5. Partitions
The customer data example we took is just a small table of data, worth a few bytes of memory. But suppose the data in question is a list of all the orders made to an organisation in the past year? That is a huge data file! Remember that brokers are just nodes in a distributed cluster with limited storage ability.
In such situations, a single broker might not have the space to store a single data pipeline. To solve the problem, a user has to divide the data file into multiple “partitions” and store them in multiple brokers. Hence, partitions are required when the topic being transferred is very large.
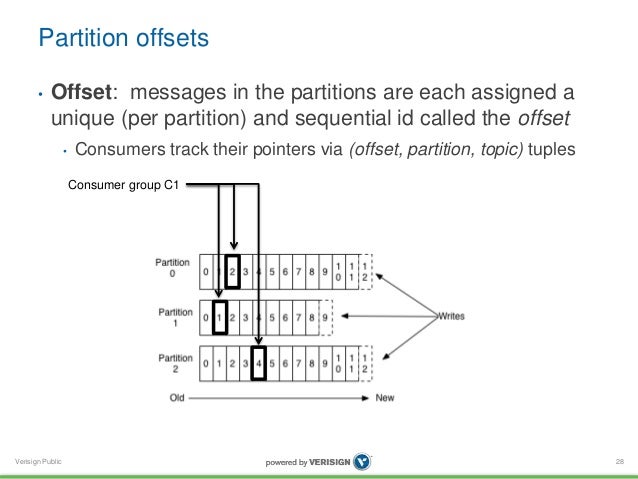
6. Offset
Dealing with large data files can lead to one very big problem! Suppose that, as in the previous example, we have a massive data file of all of last year’s orders stored between three brokers B1, B2, and B3. Where in this huge and partitioned file, do I find the data of a particular customer?
Don’t get us wrong – Kafka’s job is not to sort or search the data in its storage – but it still needs to know where (and if!) the data exists at a certain point in its memory. It is because knowing this is important to establish that the dataset is intact.
If you don’t keep track of the data entering your server, how do you determine if a single instance of the dataset has become corrupt? You can’t! Kafka’s solution to this issue is this:
Every piece of data that enters a single partition is sorted in serial order. The first message that enters a partition is given an “offset” of 0. The second message is given an offset of 1, and so on. This means, that to identify any arbitrary message in a Kafka cluster, we need to know three things: (1) the Topic of the message, (2) which Partition the message is in, and (3), the offset of the message.

7. Fault Tolerance
So far, it seems like Kafka has it all figured out, doesn’t it? But recall that Kafka runs on a series of commodity hardware computers interconnected to form a cluster.
Also recall that large files are often stored between more than one such computers. What happens if a single broker crashes and the data in it (that is, a partition of a topic) is lost? Do we lose the entire file? Luckily, no. Kafka, just like Hadoop, has a fault tolerance protocol incorporated in it. Every topic that is created in Kafka is stored at more than one location. Here are the bare basics of this protocol:
- The number of different copies of a topic that exist in Kafka’s servers is called the replication factor. Typically, a replication factor of 3 is considered suitable – that is, each piece of data is stored at three independent locations. This means that even if your two of your systems crash, you can still access your data.
- To automate this process, Kafka defines leader and follower brokers. A leader broker is one that primarily stores the data in question and communicates with the producer and the consumer. Follower brokers simply store copies of the data and do not participate in any negotiations until the leader broker breaks down.
8. ZooKeeper
By now, we’ve covered pretty much the bulk of Kafka’s workings, except for one key aspect: this wildly intricate data integration framework requires comes across hundreds of decision making points in a single day. Here are some examples of decisions that need to be made routinely for Kafka to work:
- I have hundreds of producers and consumers, and a certain number of brokers. How do I decide which broker to appoint to negotiate the data flow between which producers and which consumers?
- How do I determine which topics are to be partitioned, and how many partitions there should be?
- How do I constantly monitor which brokers are live and actively a part of Kafka at any point in time?
- How do I transfer responsibility from a leader broker to a follower broker in the event of a failure?
- How do I keep track of which consumer is allowed to gain access to which producer’s data stream?
- There are hundreds of data pipelines, and each of them has to run smoothly. How do I decide how much bandwidth each data pipeline is to get so that everything runs in a stable way?
To take all these decisions and act as the de facto “brain” of the Kafka framework, a central service available in the Kafka architecture is the ZooKeeper. In order to have Kafka function up to its potential, the ZooKeeper has to be perfectly programmed and configured.
ZooKeepers are often difficult to develop and specialised training is required to have one work your way. However, although you can find mentions of a Kafka cluster without ZooKeeper dependency on the internet, such a thing is rare – ZooKeepers are an integral and highly essential part of the Kafka architecture.

Use Cases of Kafka
If you know anything about Big Data, you’re probably aware that most of the frameworks that support it are excellent for offline processing and reporting of vast amounts of data, but tend to have some trouble with dealing with real time streams of live data.
This is where Kafka is invaluable to most corporations – it integrates live data processing with Big Data Analytics. The implications of this are massive. Let’s take just one, to give you an idea: online banking fraud detection. There are practical use cases of Apache Kafka being used to detect fraud available from Google Cloud Big Data and Machine Learning Blog, MapR, and Cloudera.
1. Online Banking Fraud Detection
If you’ve ever made an online payment using credit card, then take a moment and recall how long it took before your transaction got accepted or rejected. Mere seconds, right? But just think about what actually happened in those few mere seconds, and you’ll have your mind blown.
Two of the three cases mentioned above use a combination of the stream processing power of Apache Kafka and the superfast data analytics of Apache Spark to achieve in few seconds a job that legacy computer would take ages to complete. (Not sure what Apache Spark is? Check out our article on it here!). In short, here’s what goes down in those few seconds:
- You swipe your credit card and make a transaction request
- A web application records your transaction request and a “producer” program written by the organisation you’re dealing with transfers the relevant data to Apache Kafka.
- Your data gets stored in a Kafka broker (along with possibly a thousand other transaction requests!), which is requested by two consumer applications, Apache Spark, and Apache Flume. Simply speaking, Spark is a high speed stream processing system, while Flume excels in collecting and transporting large amounts of streaming data. Spark sends your data to a Hadoop cluster ( H1) for lightning fast fraud analytics, while Flume transfers your data to a second Hadoop cluster (H2) for things like offline processing and machine learning. (You can read more about Hadoop in our article here).
- Over time, H2 will generate insights from its existing database that help in detecting future fraud. H1, on the other hand, analyses your transaction in real time and hands back a “verdict” to Kafka.
- This time, Apache Spark is the “producer” application which sends the verdict to Kafka’s brokers, and the consumer is the payment gateway from which you made your transaction request
- Based on the information received from Kafka, the payment gateway either accepts or rejects your transaction.
Does that leave you a little bit dazed? Think, now, that in a company like Google or Amazon, possibly tens of thousands of transactions happen every second in multiple formats, and Kafka, aided by Big Data Analytics platforms, provides you a way of preventing fraudulent behaviour almost as fast as your brain can think.
There are numerous other use cases of Kafka, and it’s impossible to describe them all in a single article. However, I’m going to highlight just one more – the task that Kafka was primarily designed to perform:
2. Website Monitoring
In a website like LinkedIn, web activity is an invaluable source of new insights into customer behavior. Website activity includes searches, page views, posts, likes, updates, transactions, pretty much everything that you can do on the internet.
Kafka is used to track web activity by creating a single topic for each type of web activity. For example, a topic of page views might exist that provides a continuous real time stream of data to a Kafka broker.
This data is requested and used by a host of applications including Spark, Storm, Flume, HBase, Hive, and so on. Depending on the nature of the operation, the data can be processed either as a live feed, or offloaded onto a data lake for offline processing.
The result? Just go to LinkedIn’s website and check out the web metrics the website can provide for each viewer the moment you click on a page. Metrics include number of page views, number of primary, secondary, and tertiary connections, people you may know, the number of people connected in the local community, and so on.
When you realize that the website generates this data individually for each of its users, you get to see a glimpse of the enormous data processing that goes on under the hood.
Apache Kafka: A SWOT Analysis
| Strengths | Kafka allows real-time stream processing that makes data flow within an organisation more systematic and fault-free |
| Weaknesses | Because Kafka wasn’t originally intended for servers, it is still only a Java library with a server component. This could lead to several limitations. |
| Opportunities | Data pipelines in organisations can grow more complex and elaborate without any added workload on the IT services or data scientists |
| Threats | Kafka does a job that is highly sensitive to the success of a company’s everyday operations. High reliability is a must, lest an entire framework should tumble down. |
The Future of Kafka-esque Stream Processing
Ongoing research trends on Big Data indicate that over time, stream processing technologies such as Apache Kafka might advance to a point where real time data can be used to predict the weather, a priceless development when it comes to farming and transportation.
Moreover, online trends such as blogs and social media can be streamed to predict the chances of a civil uprising or a revolt.
Big data has come to a point where the only limit to the ends that you can achieve with it is your imagination and an appropriate coordination of computational resources. And Kafka, as you’ve just seen, is at its very center.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}